Testbed Hardware
The testbed contains the latest and next generation FPGAs. This page provides a brief overview of the different families hosted
Xilinx Alveo
 We provide both Xilinx Alveo U280 and U250 FPGAs. In the past couple of years these current generation FPGA cards have demonstrated their ability to handle HPC and data centre workloads. The main difference between the two models is in external memory, where the U280 provides 8GB of HBM2 (high bandwidth memory) and 32GB of DDR4-DRAM, whereas the U250 contains no DRAM but provides 64GB of DDR4-DRAM. Whilst the FPGAs provided by both models are largely comparable, the U250 contains slightly more FPGA resource than the U280. The differences provided by these cards makes them interesting to explore, where the on-card 64GB DDR4-DRAM of the U250 can handle large problem sizes, and the HBM2 of the U280 can make a significant difference to the performance of some workloads.
We provide both Xilinx Alveo U280 and U250 FPGAs. In the past couple of years these current generation FPGA cards have demonstrated their ability to handle HPC and data centre workloads. The main difference between the two models is in external memory, where the U280 provides 8GB of HBM2 (high bandwidth memory) and 32GB of DDR4-DRAM, whereas the U250 contains no DRAM but provides 64GB of DDR4-DRAM. Whilst the FPGAs provided by both models are largely comparable, the U250 contains slightly more FPGA resource than the U280. The differences provided by these cards makes them interesting to explore, where the on-card 64GB DDR4-DRAM of the U250 can handle large problem sizes, and the HBM2 of the U280 can make a significant difference to the performance of some workloads.
Xilinx Versal
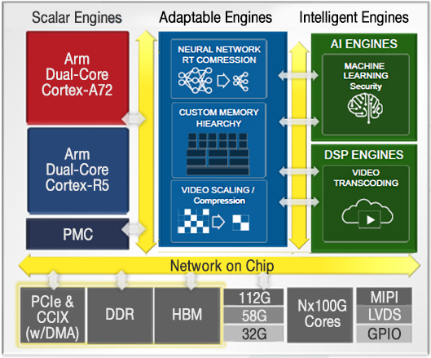 The Xilinx Versal is a next-generation FPGA board that will be released later in 2021 and we will be installing in the Autumn of this year. Known as an Adaptive Compute Acceleration Platform (ACAP), in addition to the configurable FPGA fabric the chip also provides four CPUs (two high performance A72 and two embedded style R5), along with a much improved on-chip high performance network, and AI engines. The last of these features, the AI engines, are the most exciting which act as simple high vectorised CPUs optimised for fixed-point and (single precision) floating-point arithmetic. Up to 400 AI engines are provided by the Versal chip, with the idea being that a workload can then be split across the FPGA fabric, A72 CPU, and AI engines, matching the parts of the workload which suit best to the specific hardware. The Versal has the potential to revolutionise how we write high performane codes for FPGAs, and will be very interesting to explore how the different components complement each other.
The Xilinx Versal is a next-generation FPGA board that will be released later in 2021 and we will be installing in the Autumn of this year. Known as an Adaptive Compute Acceleration Platform (ACAP), in addition to the configurable FPGA fabric the chip also provides four CPUs (two high performance A72 and two embedded style R5), along with a much improved on-chip high performance network, and AI engines. The last of these features, the AI engines, are the most exciting which act as simple high vectorised CPUs optimised for fixed-point and (single precision) floating-point arithmetic. Up to 400 AI engines are provided by the Versal chip, with the idea being that a workload can then be split across the FPGA fabric, A72 CPU, and AI engines, matching the parts of the workload which suit best to the specific hardware. The Versal has the potential to revolutionise how we write high performane codes for FPGAs, and will be very interesting to explore how the different components complement each other.
Intel Stratix-10
 The Stratix-10 is Intel's flagship FPGA and it is our plan to purchase the MX model which contains HBM2 and Optane NVRAM on the board. This will enable exploration of multiple memory spaces, especially interesting here will be the NVRAM which is slower than DDR4-DRAM but considerably larger. Therefore a key question for HPC codes will be whether the HBM2 and NVRAM can be used in conjunction to most effectively exploit the respective benefits of each. Whilst the Intel component of the testbed will be small, we only plan to have one Stratix-10 card, this is still interesting to compare and constrast against the Xilinx cards to help application developers explore a wide variety of properties to understand which most effectively suits their applications.
The Stratix-10 is Intel's flagship FPGA and it is our plan to purchase the MX model which contains HBM2 and Optane NVRAM on the board. This will enable exploration of multiple memory spaces, especially interesting here will be the NVRAM which is slower than DDR4-DRAM but considerably larger. Therefore a key question for HPC codes will be whether the HBM2 and NVRAM can be used in conjunction to most effectively exploit the respective benefits of each. Whilst the Intel component of the testbed will be small, we only plan to have one Stratix-10 card, this is still interesting to compare and constrast against the Xilinx cards to help application developers explore a wide variety of properties to understand which most effectively suits their applications.